高速ラベル認識による異種缶混入防止
多種類の製品が流れる生産ラインで、混入した異種カンの識別を実現する事例です。なかでもジュース類にアルコール飲料が混じると社会的問題となるため、生産性を追求しつつも、慎重に判別する必要があります。そこで処理速度よりも、識別可能性についての検討に優先して取り組みました。


「教師あり学習」の一つの手法である、「決定木」を用い、複数の決定木にて推論を行う『Random Forest』の検討を行いました。
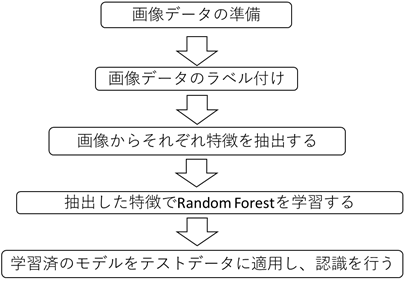
「画像データの準備」では、異なる角度から撮影した缶の画像を用意します。照明は一定で撮影角度も固定します。画像の数は多いほど望ましいでしょう。
「画像データのラベル付け」では、画像の内容を確かめて目視でラベル付けをします。
「画像からそれぞれ特徴を抽出する」では、画像の差異を反映できる特徴を抽出します。特徴の優劣がその後の学習に影響するため、特徴の設計は重要です。特徴の次元数と処理時間のトレードオフに注意が必要です。
・色特徴
赤枠領域を三等分し、それぞれ特徴を抽出します。RGBの絶対値とRGBの相対的な割合を6×3=18次元で表します。
・模様特徴
共起行列によって模様特徴を表現します。3つの距離と2つの角度を組み合わせた共起行列のcontrast, homogeneity, energy, correlationの4つの組み合わせより、3x2x4=24次元で表します。
こうして色やテクスチャ等の情報を42次元ベクトル化します。

「抽出した特徴でRandom Forestを学習する」では、データを複数の決定木に入力し、それぞれ学習して判別します。決定木ごとに異なる判別基準を持ち、それぞれ木の判別結果の多数決を取って、フォレストの判別結果とします。
木の本数と処理時間のトレードオフに注意が必要です。またランダムに判別基準を決める仕組みですから、最善なモデルを得るためには試行錯誤が必要です。
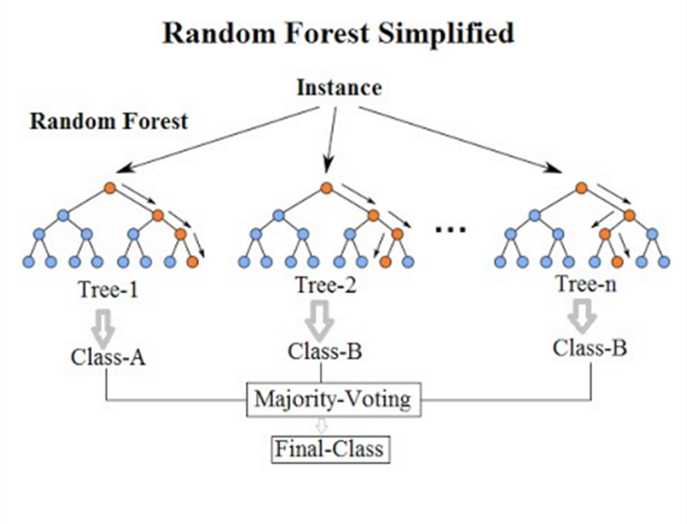
実験した結果です。缶の種類についてラベル付けします。主観による判断で13種のクラスにラベリングしました。


実験での条件設定は以下の通りです。実験データは、10種類の缶から撮影した合計120枚の写真で、それぞれの画像は300×500ピクセルです。学習データは、実験データの30%、50%、100%で行い、テストデータは全ての画像としました。学習データが増えるほど、学習済みモデルの精度向上が期待できます。
モデルの判別精度は、
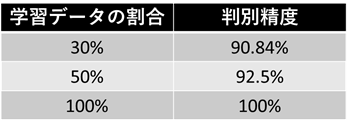
となりました。ラベルが違っても同じ缶の種類に属していることがあるため、実際に適用した時の精度はこれより高くなります。
性能についての評価ですが、1回の推論平均時間(画像の読み込みから判断がつくまで)は35msでした。2.7GHz Intel Core i5、Pythonで実装しています。実験により手法の有効性が検証されました。
お問い合わせ
開発事例に興味がありましたら、お気軽にお問合せください。
下記お電話、または「お問い合わせ」からフォームにご記入ください。
株式会社ハイシンク創研 研究開発本部075-322-7088受付時間 9:00-18:00 [ 土・日・祝日除く ]
お問い合わせ
